Trascizione video
Intelligenza artificiale. Machine Learnings. Salvatore Aranzulla. Macchine che apprendono da sole. Benvenuto o benvenuta allo spiegone del mese di Novembre. Il video in cui cerco di dare la risposta definitiva ad una singola problematica. In questo mese di Novembre proverò a rispondere alla domanda. Cos’è il Machine Learning? Iniziamo!
Ciao, io sono Alberto Olla del sito imparareaprogrammare.it e l’argomento che la Developer Society ha scelto per questo mese è il Machine Learning.
Machine Learning
Quindi le macchine che imparano. In realtà il Machine Learning ha poco a che fare con il settore di cui mi occupo ovvero lo sviluppo web o lo sviluppo full stack in generale. Quindi per parlare del Machine Learning mi sono documentato e mi sono rivolto alle persone più autorevoli che conoscessi del settore. Quindi tendenzialmente la mia ragazza che ha conseguito la laurea magistrale con tesi proprio sul Machine Learning e Data Mining, e poi anche a degli amici che stanno facendo il dottorato nell’università di Cagliari. Mi hanno dato dei link utili, dei link molto interessanti in cui torneremo a parlare più tardi. E poi, ovviamente, sono anche andato su google, ho cercato delle informazioni e ho trovato un sacco di guide, di tutorial, anche di video su YouTube che spiegano in maniera semplice dei concetti che in realtà sono abbastanza complicati. Quindi gli obiettivi di questo video sono essenzialmente tre:
- Il primo – cercare di farti capire come fa un computer ad imparare, ok? E vedremo da lì.
- Il secondo – quali sono gli strumenti che uno sviluppatore può subito utilizzare per andare a scrivere degli algoritmi di Machine Learning o per andare ad usarli direttamente.
- E il terzo – quali sono i migliori corsi gratuiti, e-book, guide, per imparare che cos’è il Machine Learning e per andare a fare i primi esperimenti.
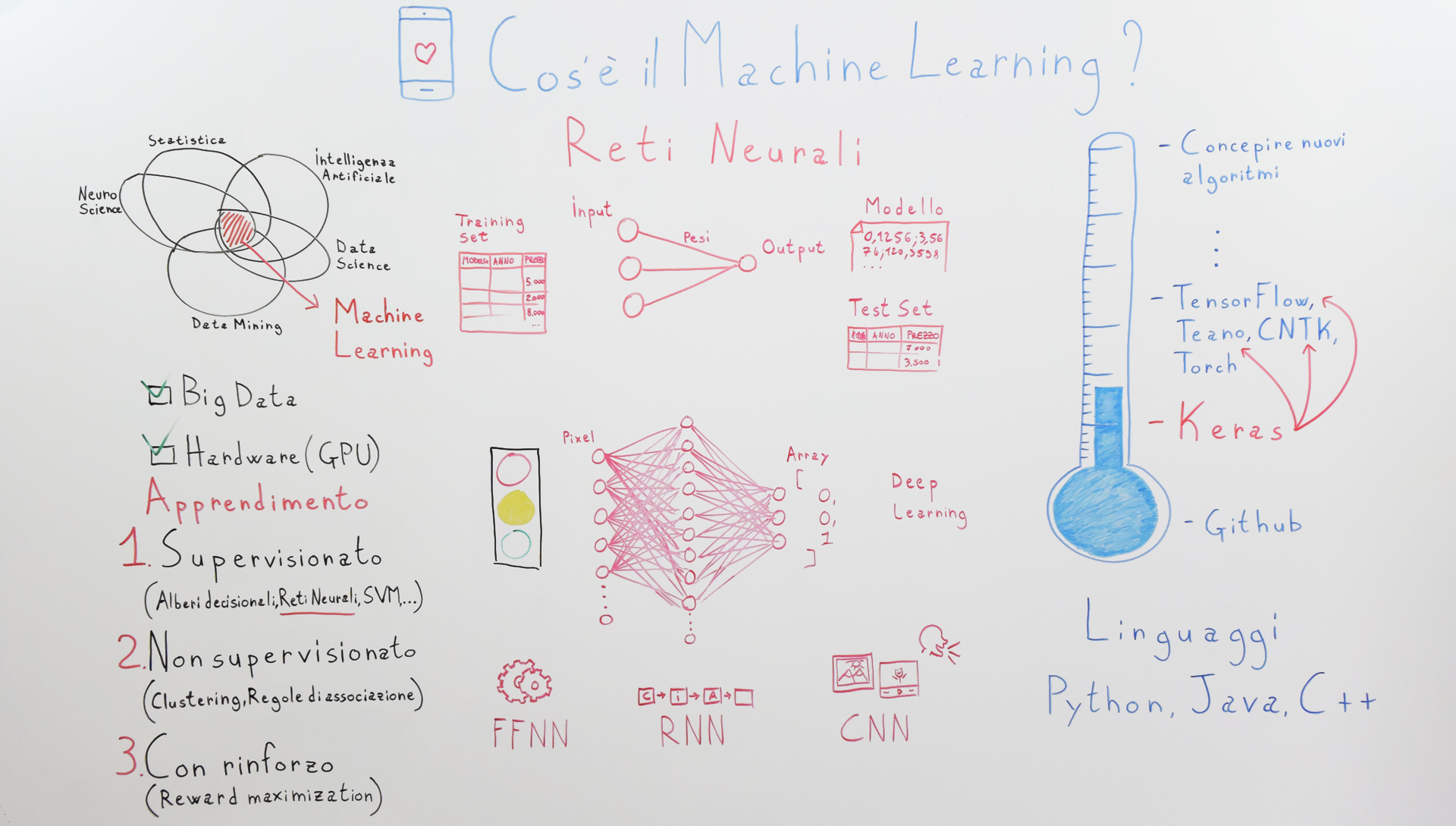
Quindi iniziamo e partiamo da lontano. In realtà le macchine che imparano da sole non sono un argomento nuovo, anzi. Sono state sviluppate e ideate sin dagli anni ’60 all’interno di quello che era l’ambito accademico, ok? Il Machine Learning in sé è un insieme di idee, di tecniche e di metodologie che provengono da aree diverse, quindi abbiamo la Statistica, il Data Science, il Data Mining, l’intelligenza artificiale, si intrecciano tutte queste metodologie e vanno a creare quindi quelli che sono gli algoritmi di Machine Learning.
Ora, negli ultimi anni si parla così tanto di Machine Learning perché effettivamente tutto quello che erano questi studi che si sono sviluppati in ambito accademico si sono spostati in ambito industriale. Ovvero, all’interno dei nostri cellulari, all’interno delle nostre app, all’interno dei dispositivi che compriamo e degli oggetti che utilizziamo. Quindi noi vediamo il Machine Learning un po’ dappertutto, anche nel nuovo iPhone o nel nuovo Huawei, se ci pensate.
Ora perché si sta spostando dall’ambito accademico, quindi dagli studi che sono stati fatti, all’ambito industriale?
Per due principali fattori.
- Il primo: I Big Data
- E il secondo: l’Hardware
Con Big Data intendiamo la grande mole di dati che vengono create ogni giorno all’interno di internet che vengono inserite. Prova a pensare ai post su Facebook, ai video che vengono caricati su YouTube, o anche semplicemente all’utilizzo che noi facciamo del cellulare. Stiamo generando dei dati che inviamo da qualche parte o anche alle smart tv o a tutti quei dispositivi chiamati smart, quindi la lavatrice intelligente, la tv intelligente, la macchina intelligente. Raccolgono delle informazioni, le inviano da qualche parte. All’interno di queste informazioni che vengono salvate, c’è qualcosa che è più rilevante rispetto a qualcosa altro, ok? Ma come facciamo ad analizzare delle enormi quantità di dati? Non possiamo mica metterci una persona che si guarda il database e si guarda tutti i dati e cerca di capire cosa ha senso, cosa può essere usato per il marketing, cosa può essere usato per magari andare a influenzare quelle che sono le vendite o per creare un nuovo prodotto e così via. Non possiamo farlo manualmente, ma bensì dobbiamo utilizzare degli algoritmi che lo faccia rimanere automatico.
Il secondo punto: l’Hardware. Questo perché in realtà gli algoritmi di Machine Learning non sono altro che una serie di calcoli matematici più o meno complessi che vengono eseguiti, ok? Quindi per poter eseguire questi calcoli matematici, è richiesto un minimo di potenza di calcolo che noi abbiamo anche all’interno dei nostri cellulari, quindi il fatto che l’hardware si sia evoluto così rapidamente ed il fatto che anche i cellulari abbiano una potenza di calcolo sempre maggiore, basti pensare all’ultimo iPhone x, ci permette di far girare all’interno del cellulare, anche degli algoritmi di Machine Learning.
L’altro punto importante sono le GPU. Sicuramente ne hai sentito parlare se il tuo amico si è comprato un computer da 4000€ per il gaming, quindi per far girare i giochi di ultima generazione. La GPU non è altro che la potenza di calcolo della scheda video che inizialmente è stata concepita per andare a renderizzare, quindi per mostrarti, quelli che sono i pixel in un ambiente 3D. I ricercatori si sono accorti che utilizzando la GPU per elaborare quelli che erano i calcoli del Machine Learning si otteneva un enorme incremento di prestazione, quindi gli stessi calcoli potevano essere effettuati in maniera molto più veloce. Ottimo punto a favore. Ora andiamo alla parte più succulenta.
Come fa un computer ad imparare?
Come può imparare qualcosa e ripeterla nel tempo? Essenzialmente i metodi di apprendimento sono tre e sono:
- Apprendimento supervisionato
- Apprendimento non supervisionato
- Apprendimento con rinforzo

Apprendimento Supervisionato
Li vedremo uno alla volta. Innanzitutto, l’apprendimento supervisionato si basa sul concetto di addestramento, cioè noi diamo in pasto al nostro algoritmo sia i dati da analizzare sia i risultati che noi ci aspettiamo che l’algoritmo ci restituisca. In questo modo sarà l’algoritmo ad addestrarsi automaticamente, cercando di restituire quello che era il valore di output che noi ci aspettavamo.
Facciamo un esempio pratico. Immagina di lavorare all’Agenzia delle Entrate. Quindi abbiamo un bel database di tutti quelli che sono gli italiani. Sappiamo quelli che sono gli evasori, quelli che siamo riusciti ad individuare. Ok? Ora prendiamo questi dati, ovvero i dati di cui abbiamo gli evasori e i non evasori, li diamo in pasto al nostro algoritmo di apprendimento passandogli anche il valore. Cioè se una determinata persona è un evasore o meno, ok? Il nostro algoritmo apprenderà in base ai dati che noi gli abbiamo passato e poi successivamente, la cosa molto importante, è che noi possiamo passare al nostro algoritmo dei nuovi dati, quindi dopo che ha imparato e che ha appreso da tutti i precedenti evasori e non evasori noi lì possiamo inserire una nuova persona e sarà l’algoritmo a dirci se quella persona che abbiamo inserito è o non è un evasore.
Qui sta la forza dell’apprendimento supervisionato. Perché se noi abbiamo già dei dati a disposizione li possiamo far analizzare e sarà l’algoritmo a crearsi delle regole interne per capire come catalogare e come distinguere le varie persone.
Apprendimento non supervisionato
Immaginiamo sempre di avere delle informazioni, quindi un grande insieme di dati. Però a questo punto noi nei dati non abbiamo qualcosa di specifico che dobbiamo ottenere in output, quindi che dobbiamo ottenere come risultato. Nell’esempio dell’agenzia delle entrate noi volevamo sapere se qualcuno era un evasore o meno. Quindi c’era proprio una cosa specifica. Invece nel metodo non supervisionato c’è una distinzione. Abbiamo semplicemente un grande insieme di dati. Prova a immaginare magari le vendite del Mc Donald’s. Abbiamo tutti i dati del Mc Donald’s Italia, quindi tutte le vendite che il Mc Donald’s Italia ha fatto nell’arco di x mesi. Quindi in questo anno 2017. Che cosa accade? Noi vogliamo prendere questi dati per analizzarli e andare a vedere se ci sono magari delle informazioni utili che possiamo utilizzare all’interno del nostro marketing, quindi cosa possiamo fare? Possiamo utilizzare degli algoritmi di apprendimento non supervisionato, prendiamo tutti questi dati, glieli diamo in pasto e sarà l’algoritmo a trovare degli schemi, a trovare delle reazioni, a trovare dei pattern ricorrenti tra i dati e quindi a restituirci delle informazioni che potrebbero esserci utili.
Per esempio magari potrebbe dirci che tutte le persone che acquistano un Mc Flurry acquistano anche un Chicken Mc Nuggets, e questo può essere molto utile in ambito di marketing. Quindi nell’apprendimento non supervisionato noi abbiamo semplicemente tantissimi dati, non sappiamo cosa farcene con questi dati. Li diamo in pasto all’algoritmo e sarà lui a identificare delle relazioni e poi ci restituirà l’analisi.
Apprendimento con rinforzo
Per spiegarti questo concetto voglio raccontarti una storia. Mio fratello quando era piccolo stava sempre davanti a una stufa, una di quelle vecchie stufe in cui dovevi girare la manopola della bombola, far uscire il gas, accenderla, con quella griglietta che si surriscaldava. Bene. Gli piaceva stare proprio lì davanti in modo da prendersi tutto il calore e mia madre gli aveva detto “attento Matteo, stai molto attento perché se metti la mano dove c’è la griglia, ti bruci, ti ustioni” e lui “sì, certo mamma”. Dopo che mia madre è uscita dalla stanza, indovina un po’ Matteo cos’ha fatto, ha preso la sua piccola manina e l’ha messa dove c’era la griglia e quindi si è ustionato le dita. Ora, dopo che Matteo ha fatto quell’azione, ha capito effettivamente che non doveva più mettere la mano nella griglia, perché altrimenti si sarebbe bruciato. E quindi avrebbe provato dolore.
Questo è esattamente quello che viene utilizzato nell’apprendimento con rinforzo. Cioè il nostro algoritmo impara dai propri errori. Se fa qualcosa di sbagliato evita, non lo fa più. Cercherà di fare qualcosa di diverso. Quindi quando noi abbiamo un apprendimento con rinforzo, non ci serve, non partiamo dai dati, come abbiamo visto con i primi due, ma bensì abbiamo l’algoritmo libero nel suo ambiente.
Proviamo a immaginare magari un algoritmo che vogliamo far giocare a scacchi. Non andremo a fargli vedere quelle che sono le giocate dei più grandi campioni di scacchi ai mondiali, ma bensì gli diremo “algoritmo, questa è la scacchiera, queste sono le mosse che puoi fare e se vinci la partita vuol dire che hai fatto delle buone mosse, se perdi la partita significa che hai fatto delle mosse sbagliate quindi devi essere punito, evita di fare quelle mosse”. Ed essenzialmente il nostro algoritmo facendo sempre più partite anche contro sé stesso può imparare a giocare sempre meglio e sempre meglio a scacchi. Quindi abbiamo il giocatore di scacchi più forte del mondo. Ok, in realtà è un computer. Più o meno questa è la storia. Per ognuna di queste aree esistono tante tecniche che sono molto diverse tra loro. Io ti parlerò soltanto di una di queste, ovvero le reti neurali. Eccole qua.
Reti Neurali
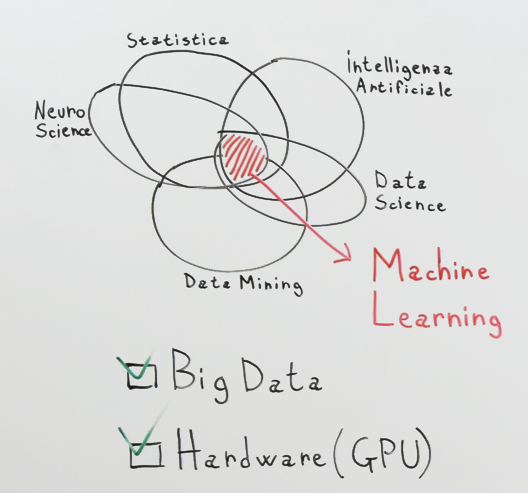
Le Reti Neurali inizialmente nascono da studi degli anni 60, 80, e così via per cercare di emulare quello che era il funzionamento del cervello umano. Ovviamente non sono riusciti a creare una cosa così complessa però sono riusciti comunque a creare qualcosa di completamente funzionante. Ed è qui, ed è in questo grafico che il computer impara.
Adesso io voglio spiegarti passo per passo come fa il computer ad imparare i semplici calcoli matematici.
Iniziamo. Innanzitutto le reti neurali, io te le farò vedere sempre in ambito di apprendimento supervisionato quindi come al solito dobbiamo partire da un training set, ovvero una serie di dati in cui noi abbiamo sia i dati noti, quelli che l’algoritmo deve andare ad analizzare, sia la risposta, quella che noi già sappiamo che è giusta. In questo modo l’algoritmo vede sia i dati, sia la risposta, e cerca di allenarsi per arrivare a quella risposta. Ok? Quindi, immaginiamo di avere questo problema. Dobbiamo predire il prezzo di una casa. Quindi abbiamo i data set con dei dati delle case, per esempio un dato di casa potrebbe essere i metri quadri, il numero di stanze, se è indipendente, è in un condominio, una villetta e così via. ok. Immaginiamo di avere questi tre dati, mh? E ovviamente abbiamo anche il prezzo, quello reale, quello che noi esseri umani abbiamo stimato. Quello che secondo noi è il prezzo giusto. Alla nostra rete neurale che cosa faremo, dovremo passare questi dati in input, ovviamente non glieli passeremo tutti assieme, ma glieli passeremo uno alla volta, quindi i dati di ogni singola casa.
Iniziamo con la prima casa. Dobbiamo passare i dati in input, la rete neurale non è altro che un insieme di funzioni matematiche, quindi ovviamente possiamo passargli in input solo i numeri. Che cosa vuol dire? I metri quadri? Glieli possiamo passare, sono numeri, non c’è problema. Il numero di stanze è un numero, glielo possiamo passare, non c’è problema. Qua ci troviamo un problema, quando dobbiamo passargli il tipo della casa, se indipendente, una villetta, in un condominio e così via. Quindi noi dobbiamo convertire questa categoria in un numero. Per esempio potremo dire lo 0 se è all’interno di un condominio, 1 se è indipendente, 2 se è una villetta. Ok. Quindi la nostra rete neurale prenderà in input questi tre numeri che non sa assolutamente cosa sono, non sa che si tratta di metri quadri, numero di stanza, non sa niente. Lui prende solo questi tre numeri, ok? Li prende in input, fa un calcolo, e cerca di arrivare in output. Essenzialmente proverà a pensare “mmh, quanto influisce l’input 1 nel calcolo dell’output?”. Quanto influisce l’input 2 e l’input 3? E prova a segnare dei pesi completamente a caso, inizialmente. Quindi l’idea. L’input 1 secondo me pesa 100, e quindi farà input 1 per 100. Input 2 quanto potrebbe pesare, 2? Input 2 per 2. Input 3 e così via. Arriva un output, sarà un numero, ovviamente un prezzo, il nostro prezzo e sarà completamente sbagliato perché avrà assegnato i pesi in maniera random. Quindi l’output finale che ci verrà restituito la prima volta sarà completamente diverso da quello che noi ci aspettavamo, ok?
E a questo punto che inizia la parte divertente perché con un calcolo matematico noi andiamo a calcolare quella che è la differenza tra l’output che ci ha restituito e l’output che noi ci aspettavamo. Questa differenza noi la andiamo ad utilizzare per andare a modificare i pesi e in questo modo alla seconda casa che andrà ad analizzare i pesi saranno già diversi e saranno già stati più o meno allineati con quella che era la differenza di prezzo precedente. Quindi noi gli passiamo sempre i dati della seconda casa, i pesi questa volta non saranno stati più dati a caso, ma saranno più o meno aggiustati, quindi tendenzialmente dovrà avvicinarsi sempre di più all’output che noi ci aspettiamo.
Questo procedimento viene ripetuto per tutte le case che noi abbiamo all’interno del nostro Dataset. Alla fine di tutto questo procedimento i nostri pesi saranno calibrati in modo tale che l’output si avvicini il più possibile a quelli che sono gli output che ci aspettavamo. Ok, ora ci basta prendere il numero di questi pesi, quindi proprio i singoli pesi e salvarli in un file.
Questo file viene chiamato Modello, è il risultato di tutto l’addestramento. Se noi abbiamo impiegato, ad esempio un giorno o addirittura un mese per addestrare la nostra rete neurale alla fine dell’addestramento otterremo questo file ed è la rete neurale già addestrata. Quindi ci basterà dirgli che questa è la struttura della rete, questo è il modello su cui ti devi basare, adesso predici i prezzi di nuove case che non hai mai visto prima. E li potremmo andare a passare per le nuove case. E sarà la rete neurale a stimare il prezzo giusto. Questa rete neurale che vi ho appena fatto vedere in realtà è molto semplice, può andare a gestire i problemi in cui gli input sono direttamente relazionati al valore di output.
Un altro esempio di rete neurale
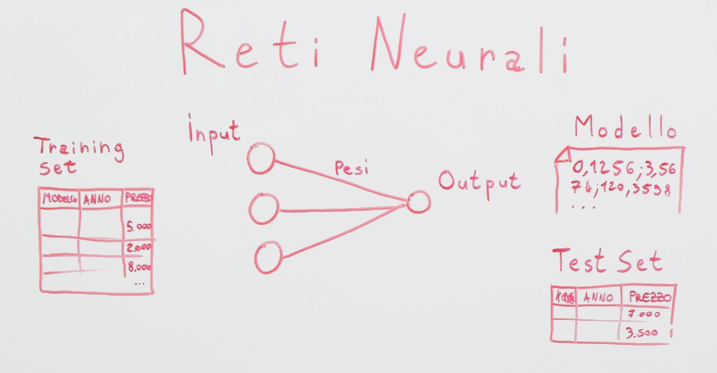
Esistono anche altri tipi di reti neurali, e vengono utilizzati principalmente per fare due attività:
- La prima è appunto questa, ovvero stimare un valore numerico singolo,
- Oppure la classificazione ovvero stimare invece se un determinato dato appartiene a una classe o un’altra.Per classe intendiamo a un tipo.
Facciamo un esempio: se io voglio creare una rete neurale che riconosca i cani e gatti quella è una classificazione. Cioè io gli do una foto in pasto, lui mi dice è un cane, è un gatto. Oppure ad esempio un semaforo. Se stiamo parlando di una macchina che si guida da sola. Quindi fa la foto del semaforo e capisce se è verde, se è rosso o se è giallo. Questo è una classificazione. Quando noi vogliamo creare una rene neurale che vada a gestire dei problemi più complessi, possiamo fare questo: possiamo aggiungere dei livelli tra quello che è il nostro input e l’output.
Questo livello che abbiamo aggiunto si chiama Hidden Layer ovvero livello nascosto e quando noi andiamo ad utilizzare un livello come questo stiamo già parlando di Deep Learning. Ora due cose voglio dirti delle reti neurali che io ho impegnato un po’ di tempo a capire.
La prima, la regola più importante è che ogni singolo input deve sempre essere un numero. Cioè se noi vogliamo fargli analizzare una foto non possiamo dargliela in pasto così, dobbiamo convertire quei pixel in qualcosa che sia un numero, proprio un numero puro così che la rete neurale lo possa utilizzare. Se noi gli vogliamo dare in pasto magari un audio? Dobbiamo convertire quelle che sono le onde del suono in un input numerico, stesso discorso per un testo. Immaginiamo che vogliamo analizzare una scritta non possiamo semplicemente dargli le parole, perché lui non le capirebbe, non le capirà mai. Dobbiamo cercare di convertire o le parole o i singoli caratteri in due numeri e poi passarli in quelli. L’output invece è molto più semplice perché essenzialmente se si tratta di un problema di classificazione dovremmo mettere un neurone per ogni classe che non vorremmo cercare di individuare o predire. Per esempio qua abbiamo detto che è un semaforo, quindi vorremmo restituirci se è giallo, se verde, se è rosso? Ok, quindi di conseguenza avremo tre output in cui ci verrà restituita una rete con valore zero o uno in base a quello che effettivamente la rete neurale ha previsto in base al training che le abbiamo fatto. Ok, questa è una cosa importante che volevo dirti.
Queste due reti neurali che ti ho appena fatto vedere in realtà sono delle reti neurali generiche cioè che tendono a risolvere praticamente qualsiasi problema perché variano i pesi in base all’output che si aspetta. Quindi noi qua magari gli possiamo passare le foto come dicevo prima del semaforo, ma gli possiamo passare anche le foto di un gatto, di un cane e di un uccello. Quindi questi tre output potrebbero essere è un gatto, è un cane, è un uccello. A lui non interessa cosa gli stiamo andando a dare, cosa rappresentano questi numeri dei pixel. A lui interessa semplicemente capire in che modo quei pixel portano ad un determinato risultato. Quindi questa rete è generica, gli possiamo passare tutto e lo risolve.
Questi due si chiamano FFNN. Lo so hanno dei nomi complicati però fidati, ha un senso. Sta per Feed Forward Neural Network. Quindi sarebbe che i dati viaggiano sempre verso destra, cioè vanno sempre in avanti. Quindi questi valori numerici vengono passati a livello successivo, vengono fatti i calcoli qua, questi valori, questi risultati di questo livello vengono passati a quello successivo e così via. Per questo si dice feed forward, va avanti.
L’altra cosa che volevo dirti è che in realtà non esistono solo queste reti neurali, anzi ce ne sono delle altre perché queste come ti ho detto sono generalizzate. Ma hanno detto “mmh, sai che c’è queste reti neurali funzionano ma sono troppo generiche, proviamo a creare delle reti minori che siano specifiche e che vadano a risolvere dei problemi mirati” e infatti l’hanno fatto e sono queste due.
Con RNN intendiamo le reti neurali ricorrenti ovvero quando dobbiamo risolvere dei problemi cui i nostri dati sono in sequenza. Quindi è importante la sequenza che hanno. Facciamo un esempio pratico. Immagina che col tuo cellulare scrivi ciao, ok? Ma non scrivi l’ultima lettera, scrivi solo cia. Ora qual è la lettera più probabile che andrai a scrivere dopo la a? Nelle reti neurali che noi abbiamo appena visto, se noi volessimo risolvere questo problema, ovvero qual è la lettera successiva che devi scrivere. Noi tendenzialmente ci baseremmo sull’ultima lettera che tu hai già scritto, quindi sulla a, ok, la nostra rete neurale prenderebbe in input la a, calcolerebbe quella che è la lettera più probabile del dizionario italiano che viene dopo la a e ti direbbe quella, probabilmente ti darebbe una lettera che non c’entra niente con la o, probabilmente te ne darebbe un’altra. Quindi, in questo caso, è molto importante sapere quali erano le lettere che c’erano prima, perché ciò che c’era prima della sequenza fa variare il risultato finale. Per questo ci serve quindi una struttura diversa. Ci serve qualcosa di ricorrente. Ok, reti neurali ricorrenti, fantastiche per le sequenze.
Andiamo avanti, le CNN. Le CNN sta per Convolutional Neural Network, anche qui abbiamo i nomi strani. Considera che nel Machine Learning qualsiasi cosa ha un nome strano perché deriva tutto dall’ambito accademico. Essenzialmente sono molto utili quando dobbiamo utilizzare delle foto, per esempio il riconoscimento facciale, oppure vogliamo analizzare dei video, immagina gli algoritmi che ci sono su YouTube, quando qualcuno carica un video per adulti, YouTube se ne accorge e in maniera molto veloce, ma non è che c’è una persona che sta lì e guarda tutti i video che vengon caricati. Ci sarà, con tutta probabilità, un algoritmo di Machine Learning che va a identificare quelli che sono i pattern ricorrenti nei video hard e nei video normali quindi li sa distinguere tra loro, stessa cosa per i copyright. Il CNN è anche utilizzato per quanto riguarda lo speech recognition, quindi essenzialmente riconoscimento vocale.
Reti neurali e Aranzulla
Ok, perfetto, adesso conosci le due cose importanti che io ci ho impiegato un po’ di tempo a capire, però non lo so mi sembra che manchi qualcosa, vorrei farti vedere qualcosa a livello pratico, fammi pensare. Tu hai qualche idea? Possiamo una rete neurale che predica l’andamento della borsa di Wall Street. Troppo banale, troppo banale, serve qualcosa di più, qualcosa che coinvolga gli italiani. Qualcosa che li faccia sentire e gli faccia dire cazzo le reti neurali sono una figata, li voglio imparare. Il calcio, possiamo predire l’andamento delle partite, vincere le schedine. Di più di più di più. Qualcosa che li coinvolga. Salvatore Aranzulla? Cosa? Salvatore Aranzulla! E che c’entra Salvatore Aranzulla.
Hop, salve! Benvenuto in questo show in cui ti farò vedere come creare una rete neurale basata sugli articoli di Salvatore Aranzulla. Seguimi. Per poter creare il tuo Aranzulla personale devi prima procurarti dei dati. Quindi devi andare sul sito aranzulla.it e creare un programmino che vada a scaricare tutti gli articoli che Salvatore ha scritto con tanta fatica nell’arco di questi anni. Per semplificarti il lavoro puoi scorrere quella che è la site, quindi in ognuno di questi link andrai a trovare una lista bella lunga di quelli che sono gli articoli che Salvatore ha scritto. Ok, adesso scrivi un programmino per scaricarli tutti. Bene. Fatto?
Andiamo avanti. Prendiamo in esempio uno dei suoi migliori articoli, ovvero come riavviare il pc. Ispezioniamo il codice html di questa pagina. Eccolo qua. Qui ci sono tutti i dati che ci servono. Però, in questo formato, non vanno bene, dobbiamo cercare di ripulirli quindi crea un codice che ripulisca tutti questi dati e li trasforma in qualcosa come questo. Fatto? Ottimo! Se hai avuto problemi con questo procedimento puoi andare sul sito http://github.com/alberto-olla/aranzulla/dataset e scaricare direttamente quelli che ho prodotto io, adesso devi installare TensorFlow all’interno del tuo computer, io ti consiglio di farlo tramite il software Anaconda.
Bene, l’hai fatto? Andiamo avanti. Adesso andiamo su GitHub e scriviamo RNN TensorFlow, in questo modo andiamo a cercare dei codici che qualche altro programmatore ha già scritto che vanno ad implementare una rete neurale ricorrente, ed è esattamente quello che ci serve per creare il nostro Salvatore Aranzulla personale. Quindi vediamo un po’ quale potremmo andare ad utilizzare. Io ho trovato questa qui, molto interessante, bene apriamola e diamogli un’occhiata. Perfetto, adesso scarica il pacchetto all’interno del tuo computer. Perfetto, eccola qui. Apriamo la cartella completa e inseriamo al suo interno il dataset di Aranzulla. Questo programmino che abbiamo scelto, andrà all’interno della nostra cartella dataset e cercherà il file chiamato con il nome Input. Quindi scegli il file che più preferisci, come puoi vedere hanno dimensioni diverse, e modifica il suo nome in input. Adesso torniamo nella cartella principale, selezioniamo il percorso e copiamolo. Apriamo anaconda e spostati all’interno della cartella. Fatto? ok. Adesso dobbiamo attivare TensorFlow, dovresti averlo già fatto durante l’installazione, ma qui dobbiamo rifarlo.
Perfetto, adesso dobbiamo lanciare l’algoritmo di addestramento, quindi scrivi Python train e andiamo ad indicare la cartella in cui si trova il file in text. Specifichiamo anche un altro parametro, ovvero la codifica. Clicca invio. Ottimo! Adesso non ci resta che aspettare che la nostra rete neurale cresca e impari a scrivere come Salvatore Aranzulla. Dopo svariate ore di addestramento, il nostro piccolo Salvatore è pronto per pronunciare le sue prime parole. Quindi scriviamo Python sample e poi andiamo a passare il parametro n che sta per i caratteri che deve generare la nostra rete neurale, proviamo. Clicchiamo invio e aspettiamo di leggere cos’ha da dirci il nostro piccolo Salvatore Aranzulla personale. Mmh, analizziamo con attenzione che cosa ha appena tradotto. Possiamo subito vedere che a volte aggiunge il tag P, proprio come fa Salvatore. E anche il tag h2, eccolo qui.
Andiamo a leggere qualche frase e vediamo cosa dice. Per maggiori info consulta il mio post su come costruire una casa, hahaha, certo Salvatore, come no, forse hai bisogno di qualche altra ora di training. Per adesso abbiamo finito, quindi torniamo nella nostra lavagna.
Finalmente siamo arrivati all’ultima parte ed è quella a cui tengo particolarmente perché mi sono accorto che c’è un grave problema in internet. Praticamente tu vai, in un gruppo Facebook, su una pagina, o in un forum, insomma da qualsiasi parte e provi a chiedere, ragazzi voglio imparare il Machine Learning, da dove devo iniziare? La maggior parte delle persone ti vanno a consigliare dei testi di statistica, di matematica, insomma roba molto tecnica e ti dico “ah, per poter utilizzare il Machine Learning devi prima avere delle solide basi in tutte quelle che sono le aree che effettivamente hanno portato alla nascita di questa nuova tecnologia o comunque di questo nuovo filone”. In realtà mi sono accorto che non è così.
In queste ultime settimane mi sono documentato parecchio e ho trovato tantissime risorse online scritte da esperti della materia che ti dicono “ok, è vero, per poter essere degli esperti di Machine Learning devi conoscere e devi avere delle basi in questi argomenti, però se devi semplicemente utilizzarli, non devi per forza conoscere i dettagli dei calcoli che fanno gli algoritmi che vengono utilizzati, devi conoscere più o meno in linea teorica come funzionano, perché funzionano in quel determinato modo e soprattutto perché funzionano bene in un determinato problema”. Però nel dettaglio non devi proprio sapere come funzionano i calcoli. Questo non sono io a dirlo, ho trovato un insegnante bravissimo di un corso di Udemy, ti lascio il link in descrizione e ti andrò a spiegare anche chi è l’insegnante e perché lui può dire determinate cose. Parliamo di questo.
Come imparare il machine learning
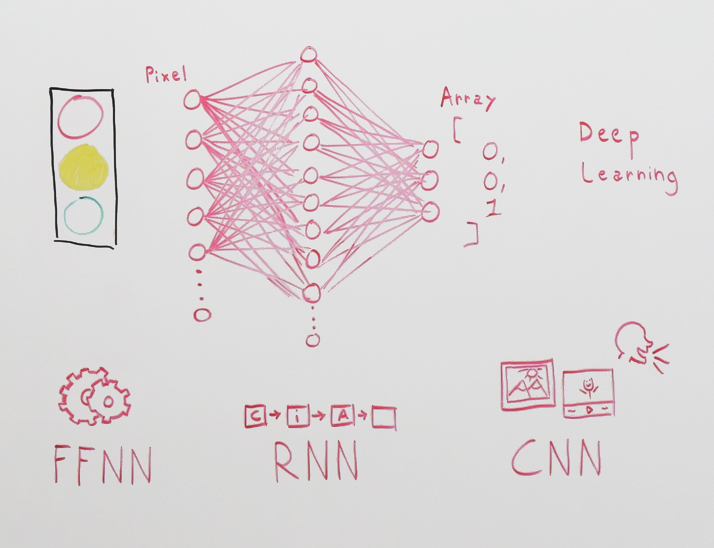
Io l’ho chiamato “il misurometro”. E serve tendenzialmente per indicare qual è il livello di Machine Learning o comunque il livello di conoscenze e di approfondimenti che devi avere per poter utilizzare queste tecnologie.
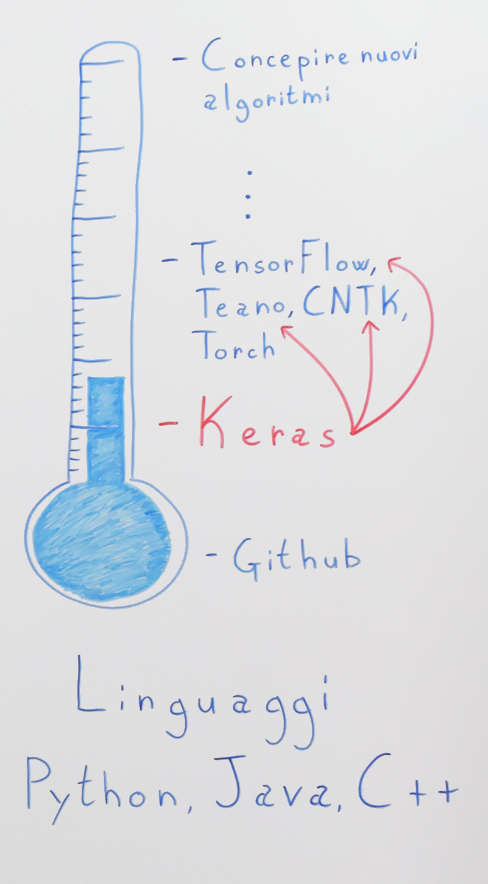
Concepire nuovi algoritmi
Ora, a livello più alto cos’abbiamo: abbiamo chi va a concepire dei nuovi algoritmi, chi allora ha concepito all’interno di un’università quelli che erano gli algoritmi di RNN, di CNN o anche di FNN, che abbiamo visto prima. Ok, per essere qua sopra, con tutta probabilità vuol dire che lavori in un centro di ricerca che può essere pubblico, privato, in ogni caso stai facendo ricerca quindi è normale che devi avere una solida base di conoscenze. Però da qui a qui esistono una marea di possibilità soprattutto per quelli che sono gli sviluppatori quindi per persone come me e potenzialmente persone come te.
Software per il machine learning
Se proviamo a scendere un pochino più in basso, troviamo una serie di librerie, quindi TensorFlow, Teano, CNTK, Torch. Questi sono degli strumenti che gli sviluppatori possono subito utilizzare quindi li puoi installare dentro un tuo computer, puoi andare a richiamare le librerie qui presenti e cosa vanno a fare. Permettono allo sviluppatore di andare ad utilizzare quelli che sono gli algoritmi più famosi già scoperti, ok? Quindi non vai a creare dei nuovi algoritmi ma vai semplicemente a ricreare degli algoritmi che sono già noti, quindi che qualcun altro ha già inventato ma li vai a riscrivere all’interno del tuo programma quindi con il tuo codice di programmazione che più preferisci. Ed essenzialmente queste librerie ti consentono di facilitarti questo compito.
La già diffusa e la più famosa è Tensor Flow che ha due grandi fattori positivi.
- La prima ovviamente è che è di google. Inizialmente l’avevano creata soltanto per il loro centro di ricerca, poi si sono accorti d’aver creato uno strumento talmente potente e talmente innovativo, diciamo così che poteva essere utile a tutti gli sviluppatori e anche a tutti quelli degli altri centri di ricerca, di tutti gli istituti, quindi hanno deciso di renderlo completamente open source. Quindi abbiamo google che gli sta dietro e questo è un grande pro.
- Il secondo pro di TensorFlow è che si occupa lui della distribuzione del calcolo. Prova ad immaginare di avere una rete neurale complessa e di avere magari una serie di computer. Hai 100 computer ognuno con una gpu potentissima e vuoi che la tua rete neurale si alleni andando a sfruttare la potenza di calcolo di tutti questi 100 computer. Come puoi fare? Lo puoi fare utilizzando TensorFlow e sarà proprio TensorFlow ad occuparsi in maniera quasi automatica della distribuzione del calcolo all’interno del tuo cluster, questa è una cosa fantastica. L’altra cosa interessante di TensorFlow è che è installabile in Device diversi, quindi potenzialmente anche all’interno di uno smartphone, molto interessante.
L’equivalente microsoft si chiama CNTK e ti consente di utilizzare C# per la scrittura degli algoritmi di Machine Learning. Ah, mi son dimenticato di dirti che TensorFlow è scritto in C++, quindi è molto performante, ma ha un’interfaccia in Python, una in java, e una mi pare in Go. Quindi può utilizzare dei linguaggi diversi per andare a scrivere effettivamente dei codici.
Quando vai ad utilizzare questi strumenti qua, è vero che sono stati pensati per il Machine Learning, però in realtà non sono altro che delle librerie che vanno a offrirti delle funzionalità di calcolo matematico, perché in realtà come abbiamo visto prima anche le reti neurali non sono altro che una serie di calcoli matematici. Quindi, qui dentro, noi abbiamo i metodi e le funzioni per effettuare questi calcoli, però sei tu che devi andare proprio a scriverli, devi dirgli ok fai questo determinato calcolo, fai quest’altro calcolo, quindi sei tu che devi gestire i pesi, devi gestire l’output, devi gestire il fatto che dopo l’output bisogna calcolare la funzione di perdita e quindi poi bisogna rimodificare i pesi, devi fare tutto tu. Ora, per poter fare tutto tu vuole dire che devi conoscere abbastanza a fondo il funzionamento delle reti neurali e degli algoritmi del Machine Learning in generale.
Software per gli sviluppatori
Però questo è un livello abbastanza avanzato, quindi proviamo a scendere leggermente nella nostra scala e che cosa troviamo: Keras. Keras è uno strumento fantastico che in realtà è scritto sopra queste librerie qua. E ti spiego a cosa serve. Essenzialmente gli sviluppatori all’interno dei centri di ricerca si erano accorti che ok è vero questi strumenti ti facilitano lo sviluppo però in ogni caso sono un po’ complessi perché devo andare proprio a scrivere tutte quelle che sono le funzioni matematiche e i calcoli algebrici. Ok. Hanno detto ci vorrebbe uno strumento che invece ci faciliti lo sviluppo, soprattutto per quelle che sono le sperimentazioni e i test dal momento che è ciò che viene fatto molto spesso all’interno dell’ambito accademico. Si sperimentano vari strumenti, vari metodi diversi e poi si valuta quello che effettivamente funziona meglio. Ed è stata creata quest’altra libreria che essenzialmente cosa fa. Va ad utilizzare sempre le funzionalità di questa libreria, ma sta a un livello sopra.
Quindi se qui abbiamo TensorFlow e tutti gli altri e qui sopra abbiamo Keras, noi andremo a scrivere un codice in Keras, che magari sono 10 righe di codice, e in realtà questo codice Keras non è altro che un codice di TensorFlow in cui magari ce ne sono 100 o 50 righe di codice. Quindi ci semplifica tantissimo la vita ed è stato appositamente pensato per il Deep Learning. Quindi fantastico strumento. Già a questo livello vediamo quanto è diventato più facile creare qualcosa e utilizzare le reti neurali.
Algoritmi pronti all’uso
Proviamo a scendere un gradino più in basso. Tac. Cosa troviamo? GitHub. Sì, in GitHub troviamo una marea di progetti open source che noi possiamo scaricare, installare e utilizzare all’interno del nostro computer che vanno a fare già un utilizzo delle reti neurali o di altri algoritmi di Machine Learning. Quindi anche se noi effettivamente non abbiamo ben chiaro come funzionino questi algoritmi, ma magari sappiamo programmare e siamo in grado di leggere dei codici, possiamo individuare innanzitutto quello che è l’algoritmo che ci interessa.
Magari per esempio abbiamo un problema di analisi delle immagini? Possiamo scaricare una rete neurale di CNN quindi andiamo su GitHub, cerchiamo CNN, andiamo a guardare il linguaggio che conosciamo meglio, se conosci Python sei avvantaggiato, ok, ti scarichi un progetto che è già stato creato per andare ad implementare una rete neurale CNN. E ti vai a guardare i codici, ma non solo, puoi anche testarlo col tuo computer. Se magari hai un amico che ha speso 4000€ per appunto prendersi un computer da gaming con una fortissima GPU, puoi scaricarti il progetto, installarlo sul computer del tuo amico e lanciare la tua rete neurale che va ad addestrarsi in base a quelli che sono i dati che tu gli dai. Quindi se sei un programmatore puoi andare a crearti un tuo dataset, glielo passi, e lei andrà a fare tutto il resto. È veramente figo, ci sono tantissimi progetti a disposizione tutti gratis.
Linguaggi più usati nel settore
I linguaggi che vengono utilizzati in queste librerie e in generale nel Machine Learning sono essenzialmente uno: ovvero Python. Python regna praticamente ovunque in cui ci siano calcoli matematici complessi. Quindi anche all’interno di quelli che sono gli ambiti universitari e accademici si va quasi sempre ad utilizzare Python. Per tutto quello che è scientifico c’è Python. Anche qui abbiamo il Machine Learning quindi calcoli matematici e ovviamente Python viene utilizzato praticamente da tutti.
In realtà puoi utilizzare anche dei linguaggi diversi: TensorFlow, CNTK, e anche gli altri ti offrono delle interfacce proprio per utilizzare dei linguaggi come java, Go, C#, c++ e così via. Potenzialmente puoi utilizzare qualsiasi linguaggio, anche per javascript esistono delle librerie che ti permettono di creare delle reti neurali direttamente in javascript. È interessante anche questo.
Risorse gratuite e non per imparare il machine learning
Ora quello che vi volevo dire è che ho creato una lista di risorse, tutte quelle che ho trovato, le più interessanti per quanto riguarda il Machine Learning e il suo apprendimento, quindi lo studio.
Corso online
La prima che vi voglio consigliare è un corso che ho trovato su Udemy, ve l’ho accennato prima ed è fatto da un insegnante veramente bravissimo. È molto in gamba, io ho seguito qualche lezione, e ho acquistato il corso e l’ho trovato di enorme interesse. L’insegnante che ha lavorato da Amazon e anche da imdb e si occupava proprio della creazione di algoritmi di Machine Learning. Quindi per esempio quando stai guardando gli oggetti su Amazon, ti appaiono gli oggetti simili, ok, quello è un algoritmo di Machine Learning. Oppure un film? I film simili? Anche lì siamo su Machine Learning. Ecco questo insegnante ha lavorato all’interno di queste due grandissime aziende e poi successivamente ha deciso di fare un corso online in cui spiega nei dettagli cosa è andato a fare, quelli che sono le teorie che stanno dietro la creazione delle reti neurali ma soprattutto è un programmatore. Quindi ti fa vedere a livello pratico come andare a creare delle reti neurali, utilizzando TensorFlow, ma anche Keras che è uno dei miei preferiti a questo punto e lui lo utilizza a pieno all’interno del suo corso. Ed è lui che dice e che sostiene che effettivamente chi va a utilizzare queste librerie non debba avere per forza delle solide basi in matematica e statistica e così via, ma può conoscere a livello superficiale quello che è il funzionamento di queste teorie e può conoscere nello specifico come funziona quella libreria da un punto di vista del programmatore. E può comunque andare a creare delle reti neurali o comunque degli algoritmi di Machine Learning completamente funzionanti. Quindi il primo link che ti lascio è questo corso online, io l’ho già acquistato e sto seguendo le lezioni. Sono tante, mi pare siano 12 ore di corso, quindi ci vorrà del tempo prima di finirlo, però se sei interessato ti invito ad acquistarlo anche tu e magari possiamo seguirlo assieme, ci possiamo dare degli aggiornamenti all’interno del gruppo di Developer Society. Le lezioni sono interessanti quindi sarebbe bello anche confrontarsi con qualcun altro che segue il corso. Può essere una cosa interessante, magari creiamo un piccolo gruppo di studenti e lo seguiamo assieme.
Canale Youtube
Il secondo link che ti lascio in descrizione è di un canale YouTube, è un ragazzo molto giovane che va a spiegare tutti quelli che sono i concetti di Machine Learning e soprattutto di reti neurali in maniera estremamente semplice, ma fa una cosa molto importante. Fa le live. Quindi lui in live ti va a creare una rete neurale e ti va a spiegare punto per punto tutti i codici che sta andando a scrivere e tutti i passaggi che sta facendo. Quindi se conosci Python puoi seguire le sue live e già da lì puoi capire il funzionamento anche perché lui man mano te lo spiega e va a creare delle reti neurali per fare le cose più disparate. Per esempio per creare delle frasi rap prese da quelli che sono i vari rapper americani, oppure per creare dei file musicali basati su Mozart e così via. Insomma fa degli esperimenti divertenti. È simpatico.
E-book
Il terzo link che ti lascio in descrizione è una guida tradotta in italiano che si intitola “il Machine Learning è divertente”. Io quando l’ho letto mi sono proprio entusiasmato.
Conclusioni
E mi ha fatto crescere la curiosità nelle reti neurali. Quindi te lo lascio in descrizione. Bene, il video è finito. Come al solito non ti chiedo di lasciare un like, non mi interessa così tanto il tuo like, mi interessa molto di più sapere quali sono le tue opinioni, dimmi cosa ti sembra sia il Machine Learning, le reti neurali, i corsi che ti ho consigliato, le guide, se vai a guardare il canale YouTube, il corso, se leggi qualcosa, fammelo sapere, ok? Sono curioso. Se vuoi scegliere quello che è l’argomento del prossimo mese ti invito a venire nel gruppo chiuso, la Developer Society, al suo interno troverai un sondaggio in cui puoi votare gli argomenti proposti dagli altri sviluppatori o puoi proporre qualche argomento tu che poi verrà votato. L’argomento più votato in assoluto, verrà preso ed utilizzato per poi fare lo spiegone del prossimo mese, ok? Io ho finito, ci vediamo il prossimo mese col prossimo spiegone.
Buon Machine Learning. Ciao!
Commenti